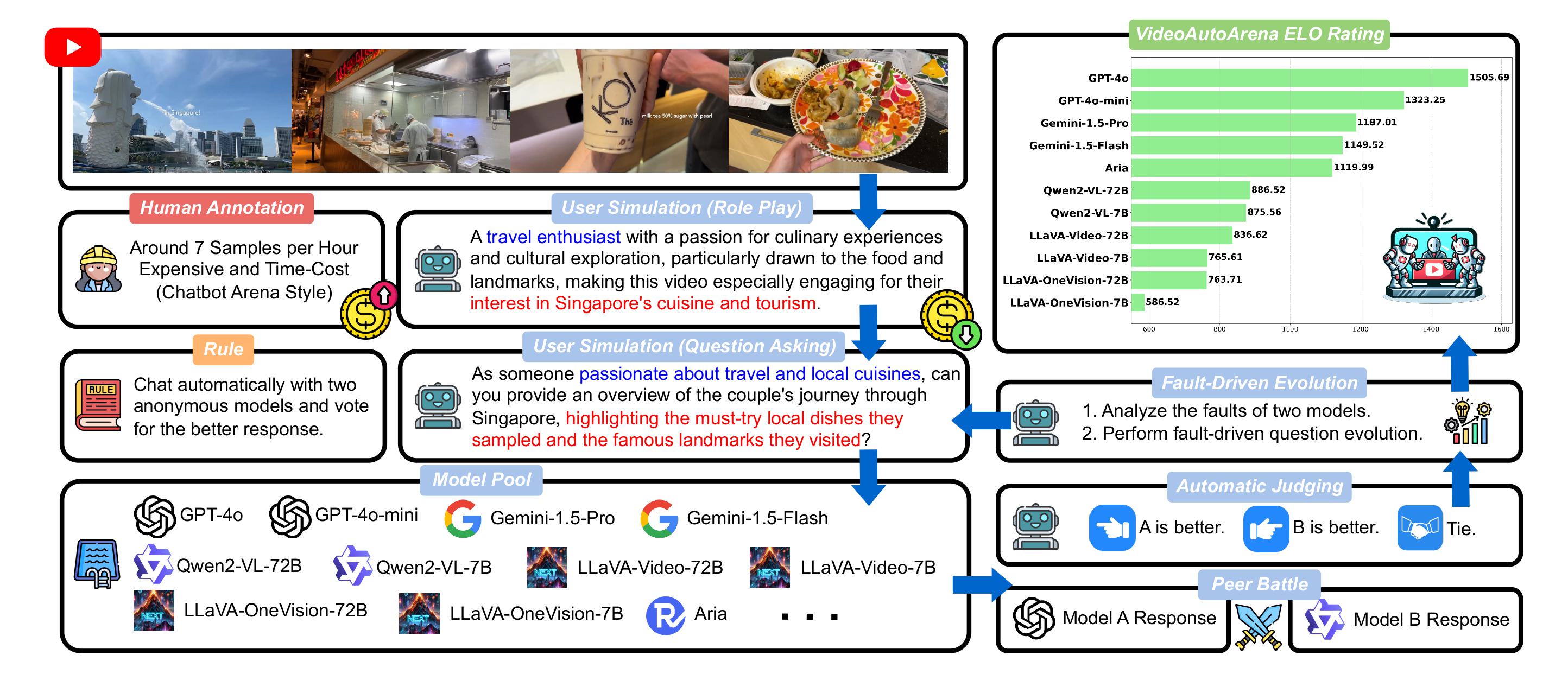
VideoAutoArena addresses a critical gap in the evaluation of LMMs for video analysis. While traditional benchmarks like VideoMME and LongVideoBench provide limited insights through multiple-choice question answering, they fail to capture the complex, open-ended demands of real-world users. With the rapid growth of LMMs, there is a need for a more dynamic and user-centric evaluation method that reflects the variety and depth of real-world video understanding tasks.
To meet this need, VideoAutoArena introduces an innovative, automated pipeline that rigorously assesses LMMs' capabilities through user simulations, peer battles, and fault-driven evolution. This approach enables continuous, scalable comparisons of model performance, capturing nuances in video comprehension that traditional methods overlook. The modified ELO Rating System ensures fair, dynamic assessments, while fault-driven evolution progressively challenges models to improve their performance in complex, real-world scenarios.
Furthermore, VideoAutoBench simplifies the evaluation process by integrating human-annotated outcomes with GPT-4o's automated judgments. This combination allows for a quicker, more accessible assessment framework without sacrificing the depth and user-centric approach of VideoAutoArena. Together, these benchmarks offer a cost-effective, scalable solution for evaluating LMMs in video understanding, ultimately pushing the field toward more robust and user-relevant video analysis models.